대용량 데이터를 효율적으로 로드해야 하는 경우 일반적으로 정규화 같은 데이터 전처리가 필요하다. 또한 간편한 수치형 필드로만 구성되어 있지 않기 때문에 원-핫 인코딩, BoW 인코딩, 임베딩 등을 사용하여 인코딩 되어야 한다. (= 매우 고달프고 어렵다.)
메모리 용량에 맞지 않는 아주 큰 규모의 데이터셋으로 딥러닝 시스템을 훈련해야 하는 경우, 텐서플로의 데이터 API는 대규모 데이터셋을 효율적으로 로드하고 전처리할 수 있도록 구현되어있기 때문에 매우 효율적이다. 텐서플로가 멀티스레딩, 큐, 배치, 프리패치같은 사항을 모두 수행해주므로 사용자는 데이터셋 객체를 만들고 데이터를 읽어 올 위치와 변환 방법을 지정하기만 하면 된다.
텐서플로 데이터 API . 연쇄 변환
전체적인 데이터 API의 중심에는 데이터셋이라는 개념이 있는데 이는 연속된 데이터 샘플을 나타낸다.
텐서플로에서는 tf.data.Dataset.from_tensor_slices() 를 사용하여 데이터셋을 생성할 수 있다.

from_tensor_slices() 함수는 텐서를 받아 X의 각 원소가 아이템으로 표현되는 데이터셋을 만든다.
데이터셋이 준비되면 변환 메서드를 호출하여 여러 종류의 변환을 수행할 수 있다. 각 메서드는 새로운 데이터셋을 반환하므로 변환 데이터를 연결할 수 있다. (연쇄 변환)

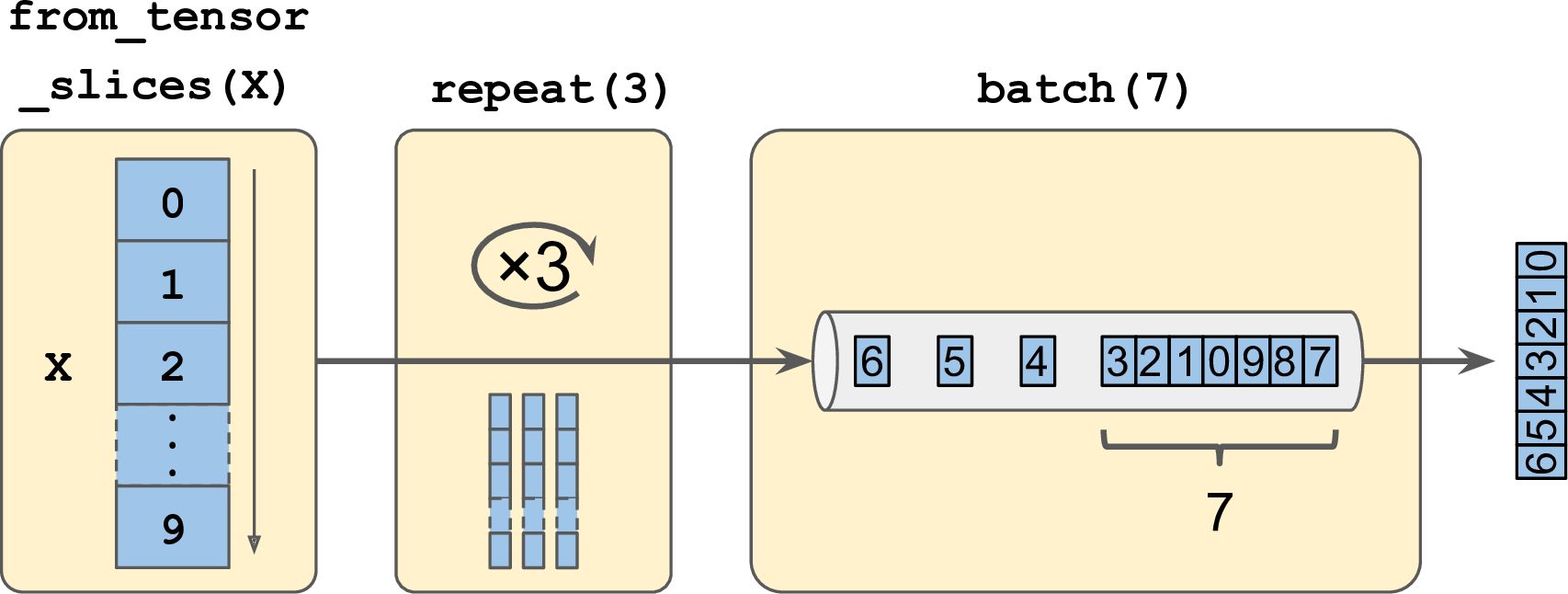
위의 연쇄 변환 메서드이다. 원본 데이터셋(아이템 10개)를 세 차례 반복하고 (repeat 3), 생성된 총 30개의 값을 7개의 배치로 나눠 각 텐서에 저장한다. (batch 7)
map() 메서드를 호출하여 아이템을 변환할 수도 있다.
모든 아이템에 *2를 하여 새로운 데이터셋을 만들기 위해서

그 외에도 데이터셋 전체에 변환을 적용하는 apply() 메서드, 데이터셋을 필터링하는 filter() 메서드, 보고 싶은 몇 개의 아이템만을 보여주는 take() 메서드 등이 존재한다.
텐서플로 데이터 API . 데이터 셔플링
경사 하강법은 훈련 세트에 있는 샘플이 독립적이고 동일한 분포일 때 최고의 성능을 발휘한다. 그렇다면 텐서로 이루어진 훈련 샘플은 어떻게 효율적으로 섞을 수 있을까?
가장 간단한 방법은 shuffle() 메서드를 이용하는 것이다. 이 메서드는 원본 데이터셋의 처음 아이템을 buffer_size 개수만큼 추출하여 버퍼에 채운다. 그 다음 새로운 아이템이 요청되면 이 버퍼에서 랜덤하게 하나를 꺼내 반환한다. 그리고 원본 데이터셋에서 새로운 아이템을 추출하여 비워진 버퍼를 채운다. 이 과정은 원본 데이터셋의 모든 아이템이 사용될 때까지 반복된다.
(buffer_size의 크기는 데이터셋의 크기와 비슷할 수록 좋다. 그 이유는 버퍼의 크기가 작으면 원본 데이터셋에서 뒤쪽에 있는 아이템이 새로 만들어진 데이터셋에서도 뒤에 등장할 가능성이 높기 때문이다.)

메모리 용량보다 큰 대규모 데이터셋은 버퍼가 데이터셋에 비해 작기 때문에 간단한 셔플링 버퍼 방식으로는 충분하지 않다. 뿐만 아니라 원본 데이터셋에 우연히 존재할 수 있는 가짜 패턴으로 인해 형성가능한 편향을 방지하기 위해 원본 데이터 자체를 셔플링하고 에포크마다 한번 더 셔플링하여 셔플링 효과를 높이는게 바람직하다.
또 다른 셔플링 방법은 원본 데이터를 여러 파일로 나눈 다음 훈련하는 동안 무작위로 읽어오는 것이다. 원본 데이터에서 나누어진 파일 여러 개를 무작위로 선택하고 파일에서 동시에 읽은 데이터를 돌아가면서 반환한다. 그 다음 shuffle() 메서드를 사용해 한번 더 셔플링한다.
훈련에 사용할 데이터셋이 존재하고 우리는 이미 이 데이터셋을 섞고, 훈련 세트, 테스트 세트, 검증 세트로 나누었다고 가정하자.
우선 각 세트를 CSV파일 여러 개로 나누고 해당 파일 경로들을 저장한 리스트를 생성한다.

list_files() 메서드를 이용하여 파일 경로를 섞은 데이터셋을 생성한다.

그 다음 interleave() 메서드를 호출하여 한 번에 다섯 개의 파일을 한 줄씩 번갈아 읽도록 설정한다.

이렇게 하면 5개의 다섯 개의 파일 경로에서 데이터를 읽는 데이터셋을 만들 수 있다.
'핸즈온머신러닝&딥러닝' 카테고리의 다른 글
| 심층 신경망 훈련하기 4 (0) | 2021.04.10 |
|---|---|
| 심층 신경망 훈련하기 3 (0) | 2021.04.09 |
| 심층 신경망 훈련하기 2 (0) | 2021.04.06 |
| 심층 신경망 훈련하기 (0) | 2021.04.05 |
| 케라스로 다층 퍼셉트론 구현하기-3 (0) | 2021.03.31 |