이전 포스팅은 몇 개의 은닉층만으로 이루어진 얕은 네트워크를 소개하고 직접 훈련해보았다.
고해상도 이미지에서 수백 종류의 물체를 감지하는 것처럼 아주 복잡한 문제를 다루어야 한다면 아마도 수백 개의 뉴런으로 구성된 10개 이상의 층을 수십만 개의 가중치로 연결해 훨씬 더 깊은 심층 신경망을 훈련해야 할 것이다.
이러한 경우 훈련 중에 다음과 같은 문제를 마주할 수 있다.
1) 그레이디언트 소실, 그레이디언트 폭주 문제
(vanishing gradient & exploding gradient)
--> 다양한 초기화 함수
2) 대규모 신경망을 위한 훈련 데이터가 충분하지 않거나 레이블을 만드는 작업에 비용이 너무 많이 들 수 있다.
--> 전이 학습(transfer learning), 비지도 사전훈련(unsupervised pretraining) 이 도움이 될 수 있다.
3) 훈련이 극단적으로 느려질 수 있다.
--> 훈련 속도를 높여주는 최적화 방법
4) 수백만 개의 파라미터를 가진 모델은 과대적합의 가능성이 크다. (특히 훈련 샘플이 충분하지 않거나 잡음이 많은 경우)
--> 규제 기법
1. 그레이디언트 소실과 폭주 문제
신경망은 학습 시 신경망의 모든 파라미터에 대한 오차 함수의 그레이디언트를 계산하고 경사 하강법 단계에서 이 그레이디언트를 사용하여 각 파라미터를 수정한다. 그리고 수정된 파라미터를 통해 신경망은 더 정확한 결과를 내놓게 된다.
만약에 각 파라미터 값의 변화가 신경망의 결과에 매우 작은 변화를 미치게 될 경우에는 어떻게 될까?
파라미터를 제대로 훈련시킬 수 없을 것이다. (혹은 경사 하강법이 연결 가중치를 변경하지 않은 채로 둘 것이다.)
결국 훈련이 좋은 솔루션으로 수렴되지 않게 된다. 이를 그레이디언스 소실이라고 한다.
반대로 그레이디언트가 점점 커져서 여러 층이 비정상적으로 큰 가중치를 갱신하게 된다면 그레이디언트 폭주 문제가 발생하게 된다.
이러한 문제점들은 층마다 학습 속도가 달라지게 만들어 심층 신경망 훈련을 어렵게 만든다.
2000년 초까지 심층 신경망은 위와 같은 문제로 거의 방치되었다고 한다. 2010년에 세이비어 글로럿과 요슈아 벤이오가 발표한 논문 덕분에 많이 진전이 되었다고 하는데... 이들은 활성화 함수와 초기화 방식(평균이 0이고 표준편차가 1인 정규분포)을 사용했을 때 각 층에서 출력의 분산이 입력의 분산보다 더 크다는 것을 밝혔다. 이 말은 신경망의 위쪽으로 갈수록 층을 지날 때마다 분산이 계속 커져 결국 가장 높은 층에서는 활성화 함수가 0이나 1로 수렴하게 된다는 의미이다.

1 . 1 초기화 함수를 활용한 해결 - 세이비어 초기화 & He 초기화
세이비어 초기화 (하이퍼볼릭 탄젠트, 시그모이드, 소프트맥스 등 s자 형 함수와 사용)
정확도 높은 모델은 예측을 할 때는 정방향으로, 그레이디언트를 역전파할 때는 역방향으로 양방향 신호가 적절하게 잘흘러야 한다. (신호가 죽거나 폭주, 소멸되지 않아야 한다.)
글로럿과 벤지오는 이렇듯이 적절하게 신호가 잘 흐르기 위해서는 각 층의 출력에 대한 분산이 입력에 대한 분산과 같아야 한다고 주장한다. 그리고 역방향에서 층을 통과하기 전과 후의 그레이디언트 분산이 동일해야 한다.
만약 특정 층의 입력의 개수(fan-in)과 출력의 개수(fan-out)가 같지 않다면 위의 두 가지를 보장할 수 없을 것이다.
글로럿과 벤지오는 이러한 문제점들을 해결하기 위해 각 층의 연결 가중치를 무작위로 초기화하는 방법을 제안하였다.
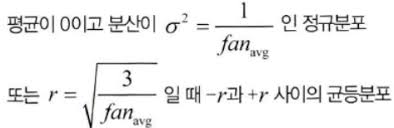
이 식은 간단하게 여러 층의 기울기 분산을 균형있게 하여 특정 층이 과도해지는 것을 방지한다는 의미이다.
He초기화 (ReLU와 그 변종들과 함께 사용)
세이비어 초기화와 유사하게 정규분포와 균등분포 두 가지로 나뉘지만 다음 층의 뉴런 수를 반영하지 않는다는 차이점이 있다.



케라스는 기본적으로 균등분포의 글로럿 초기화(=세이비어 초기화)를 사용한다. 다음과 같이 kernel_initializer = "he_uniform" 이나 "he_normal" 로 변경하여 He초기화를 사용할 수 있다.

fan - in 대신 fan - out 기반의 균등분포 He초기화를 사용하고 싶다면 VarianceScaling을 사용할 수 있다.

1 . 1 초기화 함수를 활용한 해결 - 수렴하지 않는 활성화 함수
시그모이드, 소프트맥스 활성화 함수와 다르게 ReLU함수는 특정 양숫값에 수렴하지 않는다는 큰 장점이 있다. (그리고 계산도 빠르다.)
하지만 ReLU함수는 일부 뉴런이 0 이외의 값을 출력하지 않을 수 있다는 '죽은 ReLU'로 알려진 문제가 존재한다.

이러한 문제를 해결하기 위해 LeakyReLU와 같은 ReLU함수의 변종이 등장하는데 0 이하의 값을 가질 때 아주 작은 기울기 값을 추가하여 절대로 죽지 않도록 만들어준다.

뿐만 아니라 RReLU, PReLU, ELU 등 다양한 ReLU 함수의 변종이 존재한다.

'핸즈온머신러닝&딥러닝' 카테고리의 다른 글
| 텐서플로에서 데이터 적재와 전처리하기 (0) | 2021.04.07 |
|---|---|
| 심층 신경망 훈련하기 2 (0) | 2021.04.06 |
| 케라스로 다층 퍼셉트론 구현하기-3 (0) | 2021.03.31 |
| 케라스로 다층 퍼셉트론 구현하기-2 (0) | 2021.03.29 |
| 케라스로 다층 퍼셉트론 구현하기 (0) | 2021.03.29 |