에이다 부스트
- 이전 예측기를 보완하는 새로운 예측기를 만드는 방법
- 이전 모델이 과소적합했던 훈련 샘플의 가중치를 더 높이는 것 --> 학습에 어려운 샘플에 맞춰짐
에이다 부스트 알고리즘
에이다부스트의 원리에 대해서 자세히 살펴보자.
1. 각 샘플의 가중치 w-(i) 는 초기에 1/m 으로 초기화된다.
2. 초기화된 가중치로 첫 번째 예측기가 학습되고, 가중치가 적용된 에러율 r1이 훈련 세트에 대해서 계산된다.


는 i 번째 샘플에 대한 j 번째 예측기의 예측
3. 위에서 구한 에러율 r_j를 활용해 예측기의 가중치 α_j 가 계산된다. 공식은 아래와 같다.

(η는 기본값이 1인 학습률 파라미터이다.)
에러율 r가 0.5에 가까워질수록 (1-r)/r ≒ 1, 즉 log 1 = 0 이 되므로 예측기가 0에 가까워지고 에러율이 0.5보다 크면 예측기 가중치가 음수가 된다. 반대로 예측기가 정확할수록 (= 에러율 r이 0에 가까울수록) 가중치가 커지게 된다.
(+만약 무작위로 예측하는 정도라면 가중치가 0에 가까울 것이다.)
4. 에이다 부스트 알고리즘이 아래의 식을 사용해 샘플의 가중치를 업데이트한다.

즉, 잘못 분류된 샘플의 가중치가 증가하게 된다.
5. 그런 다음 모든 샘플의 가중치를 정규화한다.

6. 마지막으로 새 예측기가 업데이트된 가중치를 사용해 훈련되고 앞서 살펴봤던 과정들이 반복된다. 이 알고리즘은 지정된 예측기 수에 도달하거나 완벽한 예측기가 만들어지면 중지된다.
7. 모든 예측기의 예측을 계산하고 예측기 가중치 α를 더해서 예측 결과를 만든다. 이때 가중치 합이 가장 큰 클래스가 예측 결과가 된다.

사이킷런은 위의 과정을 SAMME (stagewise additive modeling using a multiclass exponential loss function)라는 다중 클래스 버전의 알고리즘을 이용하여 계산하는데 가중치 α_j 를 업데이트하는 공식을 제외하고는 에이다부스트와 동일하다.

이번에는 사이킷런의 adaboostclassifier를 사용하여 200개의 얕은 결정 트리를 기반으로 하는 에이다부스트 분류기를 훈련시켜보겠다.
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=200,
#리프노트 하나와 결정노드 두 개, 앙상블은 총 200개
algorithm="SAMME.R", learning_rate=0.5)
ada_clf.fit(X_train, y_train)(+여기서 SAMME.R은 예측기가 클래스의 확률을 추정할 수 있는 경우 (predict_proba() 메소드를 사용할 수 있는 경우) 사용할 수 있는 SAMME의 변종 모델이다. 해당 변종 모델은 예측값 대신 클래스 확률에 기반하여 일반적으로 성능이 더 좋다.)
그레이디언트 부스팅
- 에이다부스트처럼 앙상블에 이전까지의 오차를 보정하도록 예측기를 순차적으로 추가
- 하지만 반복마다 가중치를 수정하는 것이 아닌, 이전 예측기가 만든 잔여 오차에 새로운 학습기를 학습
- 에이다부스트 모델과 마찬가지로 그레이디언트 부스팅 모델은 회귀 문제를 해결할 수 있는데 이를 그레이디언트 트리 부스팅, 그레이디언트 부스티드 회귀 트리 (GBRT) 라고 한다.
GRBT 예제
from sklearn.tree import DecisionTreeRegressor
import numpy as np
#잡음이 섞인 임의의 2차 곡선 데이터
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X,y)이제 첫 번째 예측기에서 생긴 잔여 오차를 활용하여 두 번째 예측기를 훈련시킨다.
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X,y2)마찬가지로 두 번째 잔여 오차를 활용하여 세 번째 예측기를 훈련시킨다.
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X,y3)세 개의 트리를 포함하는 앙상블 모델이 생겼다. 이제 새로운 샘플에 대한 예측을 만들기 위해 모든 트리의 예측을 더한다.
X_new = np.array([[0.8]])
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))해당 과정은 아래 그림과 같다.

첫 번째 행에서는 앙상블에 트리가 하나만 있어서 첫 번째 트리의 예측과 완전히 같다.
두 번째 행에서는 새로운 트리가 첫 번째의 잔여 오차에 대해 학습된 것을 알 수 있다.
세 번째 행에서는 또 다른 트리가 두 번째 트리의 잔여 오차에 훈련되어 보다 좋은 결과를 얻을 수 있었다.
사이킷런의 GradientBoostingRegressor를 사용하면 GBRT 앙상블을 간단히 훈련시킬 수 있다.
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth = 2, n_estimators = 3, learning_rate =1.0)
gbrt.fit(X,y)매개변수 중 learning_rate 는 각 트리의 기여 정도를 조절한다. 즉, 0.1처럼 낮게 설정하면 앙상블을 훈련 세트에 학습시키기 위해 많은 트리가 필요하지만 성능은 좋아진다. 하지만 이는 모델의 과대적합을 야기할 수 있으므로 주의해야 한다.

최적의 트리 수를 찾기 위해서는 조기 종료 기법 (이전 포스팅 참고)을 사용할 수 있다. 훈련의 각 단계에서 앙상블에 의해 만들어진 예측기를 순회하는 반복자를 반환하는 메서드인 staged_predict()를 사용하면 간단히 구현할 수 있다고 한다.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_val, y_train, y_val = train_test_split(X,y)
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=120)
gbrt.fit(X_train, y_train)
#에러를 최소로 만드는 n_estimators 개수를 찾는다.
errors=[mean_squared_error(y_val, y_pred) for y_pred in gbrt.staged_predict(X_val)]
best_n_estimator = np.argmin(errors)+1
#찾은 개수를 대입하여 최적의 모델을 만든다.
gbrt_best = GradientBoostingRegressor(max_depth=2, n_estimators=best_n_estimator)
gbrt_best.fit(X_train,y_train)
난 83개가 최적이라고 나왔다.
위의 방법처럼 많은 수의 트리를 훈련시켜보고 최적의 수를 찾는 대신에 조기 종료하여 최적의 모델을 구하는 방법도 있다. warm_start = True로 설정하면 사이킷런이 fit() 메서드가 호출될 때 기존 트리를 유지하고 훈련을 추가할 수 있도록 해준다. 사용자가 지정한 수 만큼의 반복 동안 검증 오차가 향상되지 않으면 훈련을 조기 종료 시킬 수 있다.
gbrt = GradientBoostingRegressor(max_depth=2, warm_start=True)
min_val_error = float("inf")
error_going_up = 0
for n_estimators in range(1, 120):
gbrt.n_estimators = n_estimators
gbrt.fit(X_train, y_train)
y_pred = gbrt.predict(X_val)
val_error = mean_squared_error(y_val, y_pred)
if val_error < min_val_error:
min_val_error = val_error
error_going_up = 0
else:
error_going_up += 1
#5번동안 검증 점수가 향상되지 않으면 break한다.
if error_going_up == 5:
break
gbrt 는 각 트리가 훈련할 때 사용할 훈련 샘플의 비율을 지정할 수 있는 subsample 매개변수도 지원한다. 예를 들어 subsample=0.25 라고 지정하면 각 트리는 무작위로 선택된 25%의 훈련 샘플로 학습된다. 이는 편향이 높아지는 대신 분산을 줄여주고, 뿐만 아니라 학습 속도를 상당히 높인다. 이러한 방법을 확률적 그레이디언트 부스팅이라고 한다.
(+가장 대표적인 그레이디언트 부스팅 모델로는 XGBoost 가 있다.
import xgboost
xgb_reg = xgboost.XGBRegressor()
#조기 종료 등 여러 기능 제공
xgb_reg.fit(X_train, y_train, eval_set=[(X_val, y_val)], early_stopping_rounds=2)
스태킹
- 앙상블에 속한 모든 예측기의 예측을 취합하는 방식 (직접 투표, 다수결 투표 등) 이 아닌, 취합된 예측들을 활용하여 새로운 예측을 만들어내는 방식 (즉, 예측한 것으로 다시 예측하는 방식)

- 세 가지의 예측기에서 예측한 3.1, 2.7, 2.9를 블랜더 혹은 메타 학습기라고 불리우는 마지막 예측기에서 다시 한 번 예측하여 최종 예측을 구하는 방식
- 블렌더를 학습시키는 일반적인 방법은 홀드 아웃 세트를 사용하는 것임

1. 훈련 세트를 두 개의 서브셋으로 나눈다. 첫 번째 서브셋은 첫 번째 레이어의 예측을 훈련시키기 위해 사용된다.
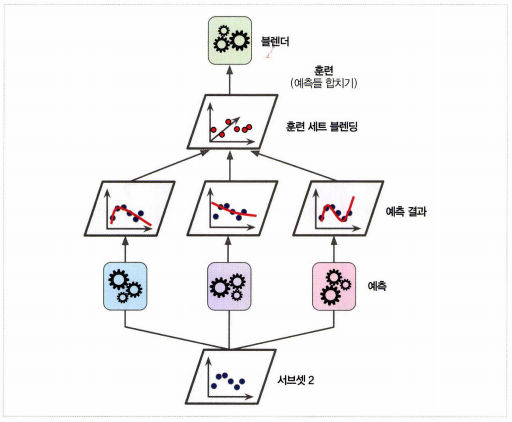
2. 그런 다음 첫 번째 레이어의 예측기를 사용해 두 번째 (홀드 아웃) 세트에 대한 예측을 만든다. 예측기들이 훈련하는 동안 이 샘플들을 전혀 보지 못했기 때문에 이때 만들어진 예측은 완전히 새로운 것이다. 그림과 같이 서브셋 1로 인해 생성된 세 가지의 예측값이 존재할 것이다. 두 번째 예측기에 대한 타깃값은 그대로 사용하고 앞에서 생성된 세 가지의 예측값을 입력 특성으로 사용하는 새로운 훈련 세트를 만들 수 있다. (새로운 훈련 세트는 3차원이 된다.)
3. 정리하자면 첫 번째 세트는 첫 번째 레이어를 훈련시키기 위한 훈련 세트로 사용되고, 두 번째 세트는 첫 번째 레이어의 예측기를 활용해 두 번째 레이어를 훈련시키기 위한 훈련 세트를 만드는데 사용된다. 마찬가지로 세 번째 세트는 두 번째 레이어의 예측기를 활용해 세 번째 레이어를 훈련시키기 위한 훈련 세트를 만드는데 사용된다.

'핸즈온머신러닝&딥러닝' 카테고리의 다른 글
| 앙상블 학습 & 랜덤 포레스트 (0) | 2021.06.16 |
|---|---|
| 결정 트리 (0) | 2021.06.14 |
| 서포트 벡터 머신2 (0) | 2021.06.11 |
| 서포트 벡터 머신 1 (1) | 2021.06.07 |
| 모델 훈련 4(로지스틱 회귀) (0) | 2021.06.07 |