케라스를 사용해 ResNet-34 CNN 구현하기
지난 포스팅에는 다양한 종류의 CNN 모델을 확인해보았다. 이번 포스팅에서는 지난 시간 다뤘던 ResNet 모델을 직접 구현해볼 것이다.
복습 차원에서 ResNet 모델에 대해 다시 한 번 살펴보자.
ResNet은 극도로 깊은 네트워크로 구성된 CNN 모델이다. 이렇게 깊은 네트워크를 훈련시킬 수 있는 핵심 요소는 스킵 연결(또는 숏컷 연결)이라 불리우는 네트워크 간 연결인데, 이는 어떤 층에 주입되는 신호가 상위 층의 출력에도 더해지는 메커니즘이라고 볼 수 있다.
예를 들어 목적 함수 h(x) 를 모델링하는 것이 목표인 신경망이 있다고 가정하자. 만약 입력 x를 네트워크의 출력에도 더한다면 (즉, 스킵 연결을 추가하면) 네트워크는 h(x) 대신 f(x) = h(x)-x 를 학습하게 될 것이다. 이를 잔차 학습이라고 한다.
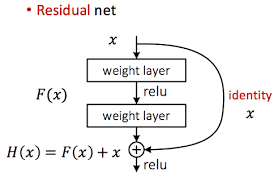
일반적인 신경망을 초기화할 때는 가중치가 0에 가깝기 때문에 네트워크도 0에 가까운 값을 출력한다. 스킵 연결을 추가하면 이 네트워크는 입력과 같은 값을 출력한다. (즉, 중간 과정을 생략한다.) 초기에는 항등 함수를 모델링한다. 목적 함수가 항등 함수에 매우 가깝다면 대부분의 경우 훈련 속도가 매우 빨라질 것이다.
또한 스킵 연결을 많이 추가하면 일부 층이 아직 학습되지 않았더라도 네트워크는 훈련을 시작할 수 있다. (잔차 유닛을 쌓았다.)
ResNet의 구조는 매우 단순하다. 드롭아웃 층을 제외하고는 GoogLeNet과 똑같이 시작하고 종료한다. 다만 중간에 단순한 잔차 유닛을 매우 깊게 쌓은 것 뿐이다. 각 잔차 유닛은 배치 정규화와 ReLU, 그리고 3*3 커널을 사용하고 스트라이드 1, 패딩 = "same" 으로 이루어진 합성곱 층으로 이루어져 있다.

특성 맵의 수는 몇 개의 잔차 유닛마다 두 배로 늘어나고 높이와 너비는 절반이 된다. (스트라이드 2인 합성곱 층을 사용해서). 이러한 경우 입력과 출력의 크기가 다르기 때문에 입력이 잔차 유닛의 출력에 바로 더해질 수 없다. (예를 들어 위의 예에서는 주황색 부분의 128, 3*3+2(s) 에서 바로 위 층까지에 영향을 미친다.) 이 문제를 해결하기 위해 스트라이드 2이고 출력 특성 맵의 수가 같은 1x1 합성곱 층으로 입력을 통과시킨다.
대부분의 CNN 구조는 일반적으로 사전훈련된 네트워크를 이용하므로 구현하기 편하다고 한다. (잘 모르겠다.)
우선 ResNet를 구현하기 위해 ResidualUnit(잔차 유닛) 층을 만들어보자.

skip_layers는 스킵 모듈로 스트라이드가 1보다 큰 경우에만 필요하다. call() 메서드에서 입력을 main_layers와 skip_layers에 통과시킨 후 두 출력을 더하여 활성화 함수를 적용한다.
이 네트워크는 연속되어 길게 연결된 층이기 때문에 Sequential 클래스를 활용하여 ResNet-34 모델을 만들 수 있다.

ResNet-34는 34개 층으로 이루어져 있는 ResNet으로 64개의 특성 맵을 출력하는 3개의 잔차 유닛, 128개 맵의 4개 잔차 유닛, 256개 맵의 6개 잔차 유닛, 512개 맵의 3개 잔차 유닛을 포함하므로 반복 루프 함수를 사용하여 구현한다. 현 필터와 이전 필터의 개수가 동일하면 스트라이드 1을 다르면 2를 출력하고 prev_filters 를 갱신한다.
케라스에서 제공하는 사전훈련된 모델 사용하기
일반적으로 구글리넷, 리넷 같은 표준 모델을 직접 구현할 필요가 없다. keras.applications 패키지에서 간단하게 로드할 수 있다.

이 코드는 ResNet-50 모델을 만들고 이미지넷 데이터셋에서 사전훈련된 가중치를 불러온다. 이 모델을 사용하려면 이미지가 적절한 크기인지 확인해야 한다.
ResNet-50 모델은 224 * 224 픽셀 크기의 이미지를 원한다. 텐서플로의 tf.image.resize() 등의 메서드를 이용하여 사용하고자 하는 이미지의 크기를 조정할 필요가 있다.

preprocess_input() 함수는 픽셀값이 0~255 사이라고 가정하여 이미지를 전처리해주는 메서드이므로 처음에 china 이미지를 255로 나눴기 때문에 다시 255를 곱한 것이다.
(Y_proba는 행이 하나의 이미지이고 열이 하나의 클래스인 행렬이다.)
마지막으로 decode_predictions() 함수를 이용하여 각 이미지가 어떠한 클래스인지를 구할 수 있다.
사전훈련된 모델을 사용한 전이 학습
충분하지 않은 훈련 데이터로 이미지 분류기를 훈련한다면 사전훈련된 모델의 하위층을 사용하는 것이 좋다. (전이 학습) 예를 들어 사전 훈련된 Xception 모델을 사용해 꽃 이미지를 분류하는 모델을 훈련해보겠다.
1. 데이터 적재

with_info = True로 지정하면 데이터셋에 대한 정보를 얻을 수 있다. 여기에서는 데이터셋의 크기와 클래스의 이름을 얻는다.
해당 데이터셋에서 train 셋밖에 존재하지 않기 때문에 이 세트를 검증 & 테스트 세트로 나눠야한다.
2. 데이터 분할

3. 이미지 전처리
이 CNN 모델은 224*224 크기 이미지를 기대하므로 크기를 조정해야 한다. (xception 패키지의 preprocess_input() 함수로 이미지를 전처리한다.)


훈련 세트를 섞은 다음 이 전처리 함수를 3개의 데이터셋에 모두 적용한다. 그다음 배치 크기를 지정하고 프리페치를 적용한다.
4. xception 모델 로드
모델의 로드와 네트워크의 최상층에 해당되는 전역 평균 풀링 층과 밀츱 출력 층을 제외시킨다. 또한 이 기반 모델의 출력을 바탕으로 새로운 전역 평균 풀링 층을 추가하고 그 뒤에 클래스마다 하나의 유닛과 소프트맥스 활성화 함수를 가진 밀집 출력 층을 놓는다.

(+ 훈련 초기에는 사전 훈련된 모델의 가중치를 동결시키자!)
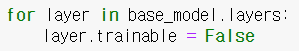
5. 모델 컴파일

몇 번의 에포크 동안 훈련하면 검증 정확도가 75~80%에 도달하고 더 이상 나아지지 않는다. 이는 새로 추가한 최상위 층이 잘 훈련되었다는 것을 의미한다. 따라서 이제 모든 층의 동결을 해제하고 훈련을 계속한다. 이때는 사전훈련된 가중치가 훼손되는 것을 피하기 위해 훨씬 작은 학습률을 사용한다.

정확도가 95%까지 올라갔다. 이런 식으로 이미지 분류기를 훈련할 수 있다.
다음 포스팅에서는 사진에서 특정 개체의 위치를 파악하는 위치 추정에 대해서 공부해보겠다.
'핸즈온머신러닝&딥러닝' 카테고리의 다른 글
| RNN과 CNN을 사용해 시퀀스 처리하기 예시 (0) | 2021.04.29 |
|---|---|
| RNN과 CNN을 사용해 시퀀스 처리하기 1 (+내용추가) (0) | 2021.04.26 |
| 합성곱 신경망을 사용한 컴퓨터 비전 3 (0) | 2021.04.15 |
| 합성곱 신경망을 사용한 컴퓨터 비전 2 (0) | 2021.04.14 |
| 합성곱 신경망을 사용한 컴퓨터 비전 1 (0) | 2021.04.12 |