CNN 구조
전형적인 CNN 구조

CNN은 보통
합성곱 층(+ ReLU) ==> 풀링 층 ==> 합성곱 층(+ ReLU) ==> 풀링 층 ==> ... 의 방식이다.
네트워크를 통과할수록 이미지는 점점 작아지지만, 합성곱 층 때문에 일반적으로 점점 더 깊어진다. (깊이 차원, 즉, 더 많은 특성 맵을 가지게 된다.)
맨 위층에는 몇 개의 완전 연결 층(+ ReLU) 으로 구성된 일반적인 피드포워드 신경망(Feedforward neural network)이 추가되고 마지막 층에서 소프트맥스 등의 활성화 층을 거쳐 예측을 출력한다.
다음 코드는 패션 MNIST 데이터셋 문제 해결을 위한 간단한 CNN 이다.

CNN이 출력층에 다다를수록 필터 개수가 늘어난다.(64 -> 128 -> 256) 이는 저수준 특성 (원, 선분 등)의 개수는 적지만 이를 활용하여 다양한 고수준의 특성을 조합할 수 있기 때문에 합리적이다. (얼굴, 가방의 형태 등)
풀링 층이 공간 방향 차원을 절반으로 줄이므로 이어지는 층에서 파라미터 개수, 메모리 사용량, 계산 비용을 크게 늘리지 않고 특성 맵 개수를 두 배로 늘릴 수 있다.
일반적으로 커널의 크기는 큰 것보다 작은 것이 좋다. 예를 들어 5 x 5 커널 1개를 사용하는 것보다 3 x 3 커널을 2개 사용하는 것이 파라미터 계산량이 적고 일반적으로 더 좋은 성능을 낸다.
다양한 CNN 구조
1. LeNet-5
- 가장 널리 알려진 CNN 구조
| 층 | 종류 | 특성 맵 | 크기 | 커널 크기 | 스트라이드 | 활성화 함수 |
| 출력 | 완전 연결 | - | 10 | - | - | RBF |
| F6 | 완전 연결 | - | 84 | - | - | tanh |
| C5 | 합성곱 | 120 | 1X1 | 5X5 | 1 | tanh |
| S4 | 평균 풀링 | 16 | 5X5 | 2X2 | 2 | tanh |
아래와 같이 생겼다.

2. AlexNet
- LeNet-5와 비슷하지만 더 크고 깊은 구조
- 처음으로 합성곱 층 위에 풀링 층을 쌓지 않고 바로 합성곱 층끼리 쌓았음
- 훈련 이미지를 랜덤하게 여러 간격으로 이동하거나 수평으로 뒤집고 조명을 바꾸는 식으로 데이터 증식을 수행
- LRN이라 부르는 경쟁적인 정규화 단계 사용 (가장 강하게 활성화된 뉴런이 다른 특성 맵에 있는 같은 위치의 뉴런 억제)
3.GoogLeNet
- 이전 CNN보다 더 깊어 에러율을 낮춤
- 인셉션 모듈이라는 서브 네트워크를 가지고 있어서 이전의 구조보다 효과적으로 파라미터를 사용한다. (AlexNet보다 10배나 적은 파라미터)
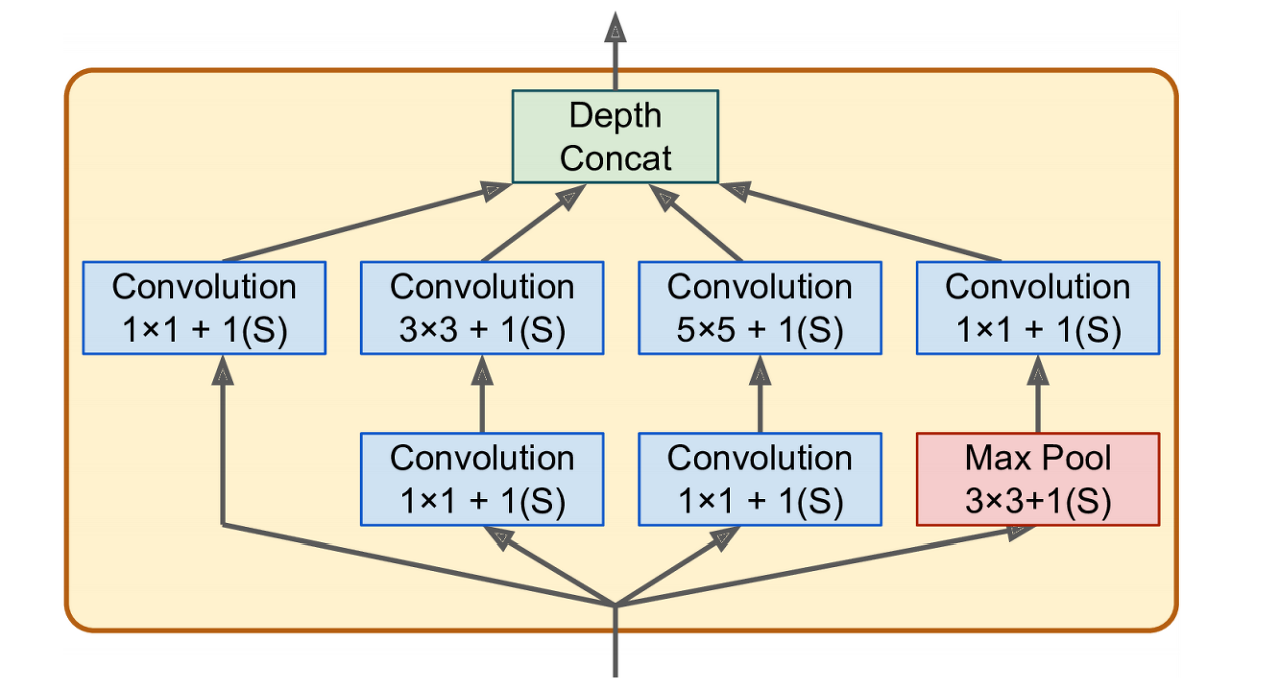
- 3x3 + 1(S) : 3 x 3 커널, 스트라이드 1, padding = "same" 를 의미한다.
- 모든 합성곱 층은 ReLU 활성화 함수를 사용한다.
- 두 번째 합성곱 층은 각기 다른 커널 크기를 사용하여 다른 크기의 패턴을 잡는다.
- 모든 층은 스트라이드 1, padding = "same"를 사용하므로 출력의 높이와 너비가 모두 입력과 같다.
- 모든 출력을 깊이 연결 층에서 깊이방향(axis = 3)으로 연결할 수 있다. (위 쪽 네 개의 합성곱 층에서 만든 특성 맵을 쌓는다.)
- tf.concat() 연산을 사용하여 구현할 수 있다.
- 1x1 커널은 한 번에 하나의 픽셀만 처리하는데 왜 사용이 되었나? -->
1. 공간상의 패턴을 잡을 수는 없지만 깊이 차원을 따라 놓인 패턴을 잡을 수 있다.
2. 입력보다 더 적은 특성 맵을 출력하므로 차원을 줄인다는 의미인 병목 층 역할을 담당한다. (연산 비용, 파라미터 개수를 줄여 훈련 속도를 높이고 일반화 성능을 향상시킨다.
3. 합성곱 층의 쌍([1x1, 3x3] or [1x1, 5x5]) 이 더 복잡한 패턴을 감지할 수 있는 한 개의 강력한 합성곱 층처럼 작용한다. (즉, 두 개의 층을 가진 신경망으로 이미지를 훑을 수 있다.)
4. 채널 사이 패턴만 감지한다.

- 처음 두 층은 계산의 양을 줄이기 위해 이미지의 높이와 너비를 4배로 줄인다. (면적은 16배 줄어든다.) + 많은 정보를 유지하기 위해 첫 번째 층은 큰 크기의 커널을 사용한다. (7x7)
- LRN 층은 이전 층이 다양한 특성을 학습하도록 만든다. (경쟁적인 정규화 단계, AlexNet에서도 사용)
- 이어지는 두 개의 합성곱 층 중에서 첫 번째 층이 앞서 설명했듯이 병목 층처럼 작용 (더 많은 패턴 인식)
- 다시 한 번 LRN 층을 활용하여 다양한 패턴을 학습할 수 있도록 한다.
- 최대 풀링 층이 계산 속도를 높이기 위해 이미지의 높이와 너비를 2배로 줄인다.
- 9개의 인셉션 모듈이 길게 이어지고, 차원 감소와 속도 향상을 위해 몇 개의 최대 풀링 층을 끼워넣는다.
- 전역 평균 풀링 층이 각 특성 맵의 평균을 출력한다. 여기서 공간 방향 정보를 모두 잃는다. 이 모델은 위치 추정이 아니라 분류 작업이므로 물체가 어디 있는지는 중요하지 않다.
- 해당 모델은 입력 이미지로 224 x 224 를 기대하는데, 총 5번의 최대 풀링 층에서 (224 -> 112 -> 56 -> 28 -> 14 -> 7) 7x7의 특성 맵을 출력하기 때문이다.
- 마지막 층은 규제를 위한 드롭아웃 층 다음에 클래스의 개수(여기서는 1000개)에 대해 분류를 진행하기 위해 1000개의 유닛과 소프트맥스 함수를 사용하였다.
4. VGGNet
- 매우 단순하고 고전적인 구조
- 2개 또는 3개의 합성곱 층 뒤에 풀링층, 다시 2개 또는 3개의 합성곱 층과 풀링 층 등장...
- 많은 필터를 사용하지만 크기는 3 x 3으로 고정
5. ResNet
- 잔차 네트워크를 사용하였다.
- 극도로 깊은 층
- 스킵 연결, 숏컷 연결을 활용하여 더 적은 파라미터를 사용해 점점 더 깊은 네트워크로 모델을 구성 (어떤 층에 주입되는 신호가 상위 층의 출력에도 더해진다.)
6. Xception
- GoogLeNet과 ResNet의 아이디어를 합쳤다.
- 인셉션 모듈을 깊이별 분리 합성곱 층으로 대체하였다.

예를 들어보자.
일반적인 합성곱 층은 타원 형태의 공간상의 패턴과 눈+코+입=얼굴이라는 채널 사이의 패턴을 동시에 잡기 위해 필터를 사용한다. 분리 합성곱 층은 이러한 공간 패턴과 채널 사이 패턴을 분리하여 모델링할 수 있다고 가정한다. 이 층은 두 개의 부분으로 구성되며 첫 번째 부분은 하나의 공간 필터를 각 입력 특성 맵에 적용한다. 그 다음 두 번째 부분에서는 채널 사이의 패턴만 조사한다. (1x1 필터를 사용한 일반적인 합성곱 층이다.)
- 분리 합성곱 층은 입력 채널마다 하나의 공간 필터만 가지므로 입력층과 같이 채널이 너무 적은 층 다음에 사용하는 것을 피해야 한다.
7. SeNet
- 인셉션 네트워크와 ResNet 같은 기존 구조 확장
- SE-Inception, SE-ResNet 이라고 불리운다.
- 기존의 인셉션 모듈, 잔차 유닛에 SE 블록이라는 작은 신경망을 추가
- SE블록이 추가된 유닛의 출력을 깊이 차원에 초점을 맞추어 분석한다. (공간패턴은 신경쓰지 않는다.)
- 어떤 특성이 일반적으로 동시에 가장 크게 활성화되는지 학습한다.
- 만약 눈, 코, 입이 자주 나오는 그림을 학습하였을때 다른 특성에서 눈과 입만 인식하였다면 코 특성 맵의 출력을 높인다.
'핸즈온머신러닝&딥러닝' 카테고리의 다른 글
| RNN과 CNN을 사용해 시퀀스 처리하기 1 (+내용추가) (0) | 2021.04.26 |
|---|---|
| 합성곱 신경망을 사용한 컴퓨터 비전 4 (0) | 2021.04.20 |
| 합성곱 신경망을 사용한 컴퓨터 비전 2 (0) | 2021.04.14 |
| 합성곱 신경망을 사용한 컴퓨터 비전 1 (0) | 2021.04.12 |
| 심층 신경망 훈련하기 5 (0) | 2021.04.11 |